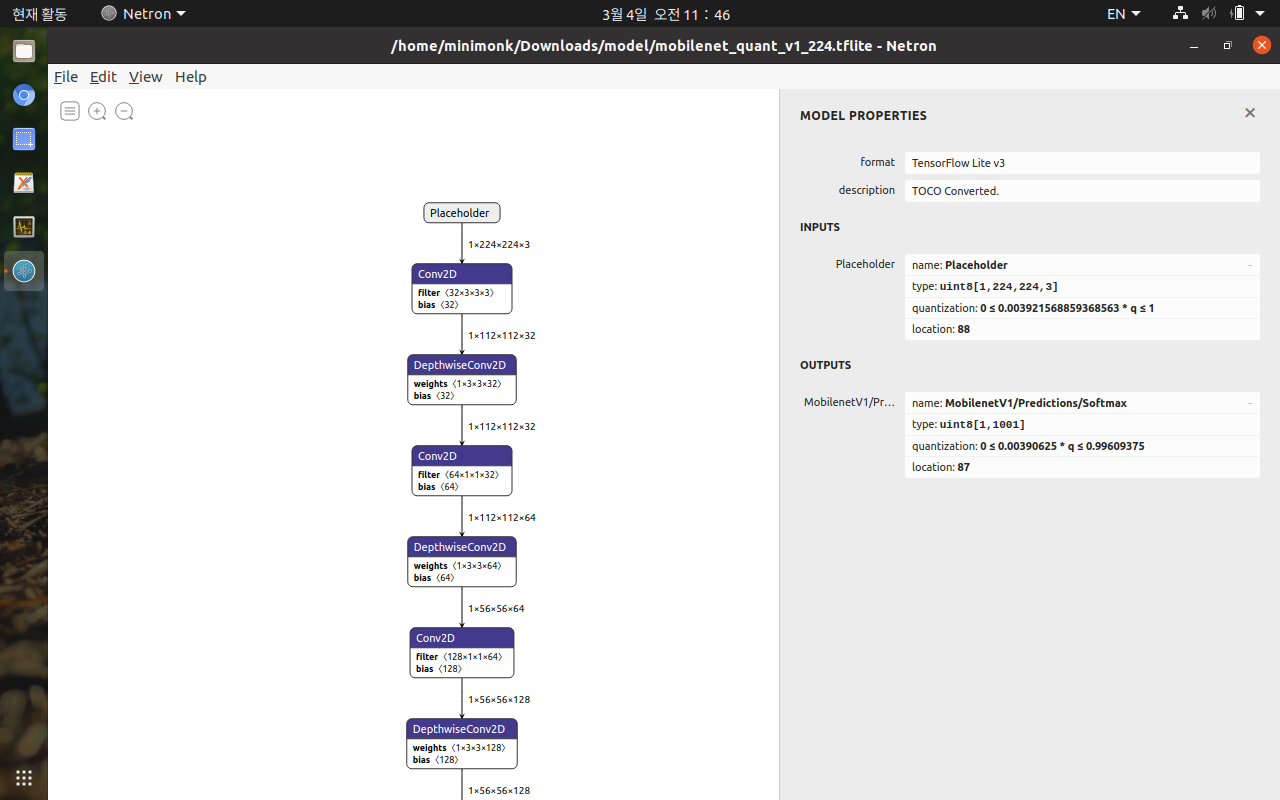
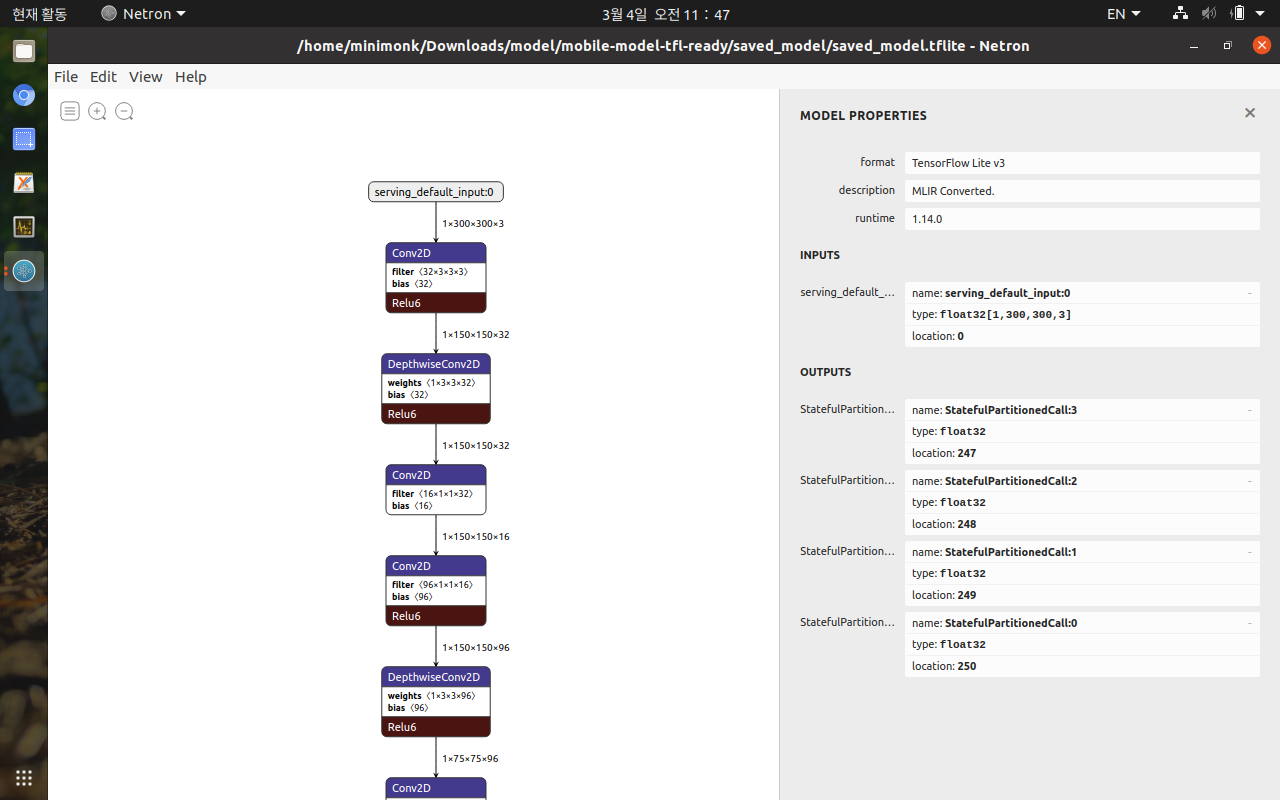
inference_input_type과 interfence_output_type을 tf.int8로 지정해주면 양자화 해주는 듯
import tensorflow as tf
converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir)
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.representative_dataset = representative_dataset
converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8]
converter.inference_input_type = tf.int8 # or tf.uint8
converter.inference_output_type = tf.int8 # or tf.uint8
tflite_quant_model = converter.convert()
[링크 : https://www.tensorflow.org/lite/performance/post_training_quantization]
[링크 : https://www.tensorflow.org/lite/performance/post_training_integer_quant?hl=ko]
+
2021.03.31
import tensorflow as tf
import numpy as np
saved_model_dir="./"
#def representative_dataset():
# for data in tf.data.Dataset.from_tensor_slices((images)).batch(1).take(100):
# yield [data.astype(tf.float32)]
def representative_dataset():
for _ in range(100):
data = np.random.rand(1, 244, 244, 3)
yield [data.astype(np.float32)]
converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir)
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.representative_dataset = representative_dataset
converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8]
converter.inference_input_type = tf.int8 # or tf.uint8
converter.inference_output_type = tf.int8 # or tf.uint8
tflite_quant_model = converter.convert()
open("saved_model.tflite", "wb").write(tflite_quant_model)[링크 : https://bugloss-chestnut.tistory.com/entry/Tensorflow-tflite를-Quantization양자화하기python]
도대체 왜 크기가 안 맞는다고 나올까..
다시보니.. 모델은 320x320 인데 244x244로 되어서 안 맞아서 그런듯.
Traceback (most recent call last):
File "conv.sh", line 21, in <module>
tflite_quant_model = converter.convert()
File "/home/minimonk/.local/lib/python3.8/site-packages/tensorflow/lite/python/lite.py", line 742, in convert
result = self._calibrate_quantize_model(result, **flags)
File "/home/minimonk/.local/lib/python3.8/site-packages/tensorflow/lite/python/lite.py", line 459, in _calibrate_quantize_model
return calibrate_quantize.calibrate_and_quantize(
File "/home/minimonk/.local/lib/python3.8/site-packages/tensorflow/lite/python/optimize/calibrator.py", line 97, in calibrate_and_quantize
self._calibrator.Prepare([list(s.shape) for s in sample])
RuntimeError: tensorflow/lite/kernels/reshape.cc:69 num_input_elements != num_output_elements (5136 != 7668)Node number 93 (RESHAPE) failed to prepare.
(1,320,320,3) 으로 바꾸니 5136에서 8136 으로 바뀌었다.
저 수식 어떻게 되어먹은거야?
RuntimeError: tensorflow/lite/kernels/reshape.cc:69 num_input_elements != num_output_elements (8136 != 7668)Node number 93 (RESHAPE) failed to prepare.
아무튼.. pipeline.config를 보니 300x300 이라 넘어는 가는데..
이건 또 무슨 에러냐..
| RuntimeError: Quantization not yet supported for op: 'CUSTOM'. |
'프로그램 사용 > yolo_tensorflow' 카테고리의 다른 글
| tensorflow quantization (0) | 2021.04.02 |
|---|---|
| tensorflow lite (0) | 2021.04.01 |
| tensorflow/lite/core/subgraph.cc BytesRequired number of elements overflowed. part 2? (0) | 2021.03.04 |
| tensorflow/lite/core/subgraph.cc BytesRequired number of elements overflowed. (0) | 2021.03.02 |
| ssd model convert for tflite (0) | 2021.02.26 |