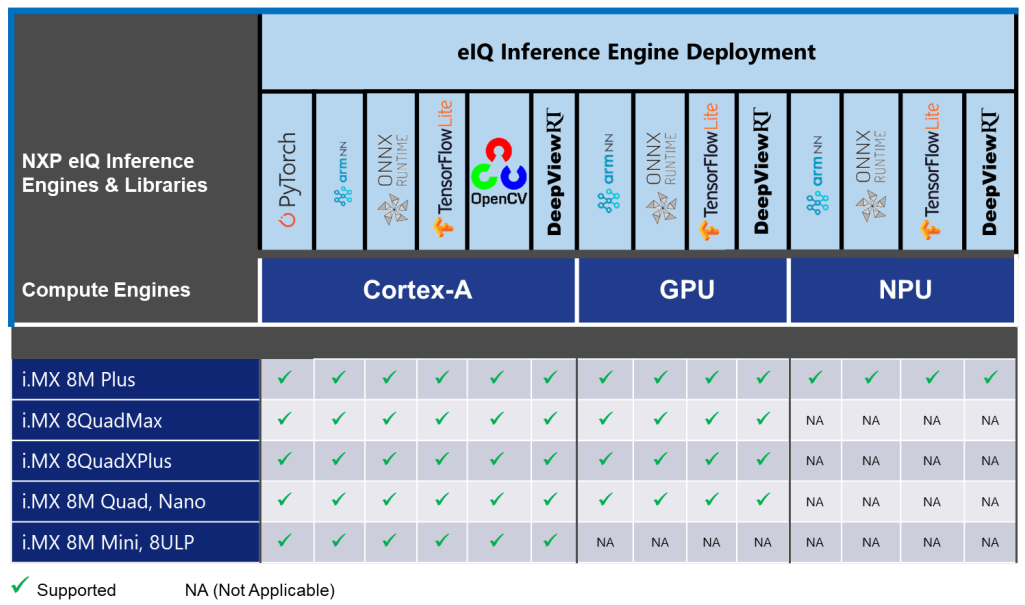
LF_v5.10.52-2.1.0_images_IMX8MPEVK.zip 파일을 받아서 이미지를 sd 카드에 굽고
부팅해서 들어가보니 경로가 좀 다르다.
tensorflow 2.5.0 버전이면.. 쓸 수 있는 건가?
| # cd /usr/bin/tensorflow-lite-2.5.0/examples # ./benchmark_model --graph=mobilenet_v1_1.0_224_quant.tflite STARTING! Log parameter values verbosely: [0] Graph: [mobilenet_v1_1.0_224_quant.tflite] Use VXdelegate : [0] Loaded model mobilenet_v1_1.0_224_quant.tflite The input model file size (MB): 4.27635 Initialized session in 1.807ms. Running benchmark for at least 1 iterations and at least 0.5 seconds but terminate if exceeding 150 seconds. count=4 first=167959 curr=162606 min=162606 max=167959 avg=164253 std=2159 Running benchmark for at least 50 iterations and at least 1 seconds but terminate if exceeding 150 seconds. count=50 first=162727 curr=163003 min=162308 max=163308 avg=162758 std=190 Inference timings in us: Init: 1807, First inference: 167959, Warmup (avg): 164253, Inference (avg): 162758 Note: as the benchmark tool itself affects memory footprint, the following is only APPROXIMATE to the actual memory footprint of the model at runtime. Take the information at your discretion. Peak memory footprint (MB): init=2.51562 overall=8.64062 # ./benchmark_model --graph=mobilenet_v1_1.0_224_quant.tflite --use_nnapi=true STARTING! Log parameter values verbosely: [0] Graph: [mobilenet_v1_1.0_224_quant.tflite] Use NNAPI: [1] NNAPI accelerators available: [vsi-npu] Use VXdelegate : [0] Loaded model mobilenet_v1_1.0_224_quant.tflite INFO: Created TensorFlow Lite delegate for NNAPI. Explicitly applied NNAPI delegate, and the model graph will be completely executed by the delegate. The input model file size (MB): 4.27635 Initialized session in 4.183ms. Running benchmark for at least 1 iterations and at least 0.5 seconds but terminate if exceeding 150 seconds. count=1 curr=4649626 Running benchmark for at least 50 iterations and at least 1 seconds but terminate if exceeding 150 seconds. count=360 first=2665 curr=2733 min=2632 max=2783 avg=2715.67 std=16 Inference timings in us: Init: 4183, First inference: 4649626, Warmup (avg): 4.64963e+06, Inference (avg): 2715.67 Note: as the benchmark tool itself affects memory footprint, the following is only APPROXIMATE to the actual memory footprint of the model at runtime. Take the information at your discretion. Peak memory footprint (MB): init=2.59766 overall=30.1836 |
label_image로 해보면.. warm up이 먼진 모르겠지만 invoke() 함수 자체는 짧게 걸리는데
그 이전에 먼가 하는게 오래 걸리는지 cpu만으로 돌리는 것 보다 4초 이상 오래 걸린다.
| # time ./label_image -w 1 INFO: Loaded model ./mobilenet_v1_1.0_224_quant.tflite INFO: resolved reporter INFO: invoked INFO: average time: 43.865 ms INFO: 0.764706: 653 military uniform INFO: 0.121569: 907 Windsor tie INFO: 0.0156863: 458 bow tie INFO: 0.0117647: 466 bulletproof vest INFO: 0.00784314: 835 suit real 0m0.142s user 0m0.385s sys 0m0.020s # time ./label_image -w 1 -a 1 INFO: Loaded model ./mobilenet_v1_1.0_224_quant.tflite INFO: resolved reporter INFO: Created TensorFlow Lite delegate for NNAPI. INFO: Use NNAPI acceleration. INFO: Applied NNAPI delegate. INFO: invoked INFO: average time: 2.797 ms INFO: 0.768627: 653 military uniform INFO: 0.105882: 907 Windsor tie INFO: 0.0196078: 458 bow tie INFO: 0.0117647: 466 bulletproof vest INFO: 0.00784314: 835 suit real 0m4.748s user 0m4.648s sys 0m0.092s |
아래는 2.1.0 버전에 맞춰서 한 구버전 문서 내용 인 듯.
| $ cd /usr/bin/tensorflow-lite-2.1.0/examples $ ./benchmark_model --graph=mobilenet_v1_1.0_224_quant.tflite $: ./benchmark_model --graph=mobilenet_v1_1.0_224_quant.tflite --use_nnapi=true ./lbl_img -i grace_hopper.bmp -l labels.txt -w 1 ./lbl_img -i grace_hopper.bmp -l labels.txt -w 1 -a 1 |
[링크 : https://www.mouser.com/pdfDocs/AN12964.pdf]
+
망할 놈(?)들 도움말이랑 다르잖아?!
| # ./label_image --help ERROR: usage: ./label_image <flags> Flags: --num_threads=1 int32 optional number of threads used for inference on CPU. --max_delegated_partitions=0 int32 optional Max number of partitions to be delegated. --min_nodes_per_partition=0 int32 optional The minimal number of TFLite graph nodes of a partition that has to be reached for it to be delegated.A negative value or 0 means to use the default choice of each delegate. --num_threads=1 int32 optional number of threads used for inference on CPU. --max_delegated_partitions=0 int32 optional Max number of partitions to be delegated. --min_nodes_per_partition=0 int32 optional The minimal number of TFLite graph nodes of a partition that has to be reached for it to be delegated.A negative value or 0 means to use the default choice of each delegate. --use_xnnpack=false bool optional use XNNPack --use_nnapi=false bool optional use nnapi delegate api --nnapi_execution_preference= string optional execution preference for nnapi delegate. Should be one of the following: fast_single_answer, sustained_speed, low_power, undefined --nnapi_execution_priority= string optional The model execution priority in nnapi, and it should be one of the following: default, low, medium and high. This requires Android 11+. --nnapi_accelerator_name= string optional the name of the nnapi accelerator to use (requires Android Q+) --disable_nnapi_cpu=true bool optional Disable the NNAPI CPU device --nnapi_allow_fp16=false bool optional Allow fp32 computation to be run in fp16 |
| static struct option long_options[] = { {"accelerated", required_argument, nullptr, 'a'}, {"allow_fp16", required_argument, nullptr, 'f'}, {"count", required_argument, nullptr, 'c'}, {"verbose", required_argument, nullptr, 'v'}, {"image", required_argument, nullptr, 'i'}, {"labels", required_argument, nullptr, 'l'}, {"tflite_model", required_argument, nullptr, 'm'}, {"profiling", required_argument, nullptr, 'p'}, {"threads", required_argument, nullptr, 't'}, {"input_mean", required_argument, nullptr, 'b'}, {"input_std", required_argument, nullptr, 's'}, {"num_results", required_argument, nullptr, 'r'}, {"max_profiling_buffer_entries", required_argument, nullptr, 'e'}, {"warmup_runs", required_argument, nullptr, 'w'}, {"gl_backend", required_argument, nullptr, 'g'}, {"hexagon_delegate", required_argument, nullptr, 'j'}, {"xnnpack_delegate", required_argument, nullptr, 'x'}, {nullptr, 0, nullptr, 0}}; |
+
그러면.. 어떤식으로 라이브러리를 빌드해서 저게 가능해진거지?
| # ldd label_image linux-vdso.so.1 (0x0000ffffa0989000) libtensorflow-lite.so.2.5.0 => /usr/lib/libtensorflow-lite.so.2.5.0 (0x0000ffffa05ab000) libm.so.6 => /lib/libm.so.6 (0x0000ffffa0501000) libstdc++.so.6 => /usr/lib/libstdc++.so.6 (0x0000ffffa032a000) libgcc_s.so.1 => /lib/libgcc_s.so.1 (0x0000ffffa0305000) libc.so.6 => /lib/libc.so.6 (0x0000ffffa0190000) /lib/ld-linux-aarch64.so.1 (0x0000ffffa0957000) libtim-vx.so => /usr/lib/libtim-vx.so (0x0000ffffa00c7000) libdl.so.2 => /lib/libdl.so.2 (0x0000ffffa00b1000) libpthread.so.0 => /lib/libpthread.so.0 (0x0000ffffa0082000) librt.so.1 => /lib/librt.so.1 (0x0000ffffa006a000) libovxlib.so.1.1.0 => /usr/lib/libovxlib.so.1.1.0 (0x0000ffff9fcd1000) libOpenVX.so.1 => /usr/lib/libOpenVX.so.1 (0x0000ffff9fa7e000) libVSC.so => /usr/lib/libVSC.so (0x0000ffff9eae2000) libGAL.so => /usr/lib/libGAL.so (0x0000ffff9e91b000) libArchModelSw.so => /usr/lib/libArchModelSw.so (0x0000ffff9e8f3000) libNNArchPerf.so => /usr/lib/libNNArchPerf.so (0x0000ffff9e8d0000) |
+
PRELU 연산자 자체는 지원하는 것 같은데 output size mistach가 원인인가?
| INFO: Use NNAPI acceleration. WARNING: Operator RESIZE_BILINEAR (v3) refused by NNAPI delegate: Operator refused due performance reasons. INFO: Applied NNAPI delegate. W [vsi_nn_op_eltwise_setup:178]Output size mismatch, expect 917504, but got 50176 E [setup_node:448]Setup node[52] PRELU fail W [vsi_nn_op_eltwise_setup:178]Output size mismatch, expect 917504, but got 50176 E [setup_node:448]Setup node[52] PRELU fail ERROR: NN API returned error ANEURALNETWORKS_BAD_DATA at line 4151 while running computation. ERROR: Node number 56 (TfLiteNnapiDelegate) failed to invoke. ERROR: Failed to invoke tflite! |
[링크 : https://www.nxp.com/docs/en/user-guide/IMX-MACHINE-LEARNING-UG.pdf]
+
warm up은 코드상으로 1회 invoke 하는 것인데 해당 작업이 4649ms 정도 소요되며
warm up 없이 1회 실행하면 대략 그 정도 시간이 소요된다.
| root@imx8mpevk:/usr/bin/tensorflow-lite-2.5.0/examples# time ./label_image -a 1 -w 0 -p 1 -c 1 INFO: Loaded model ./mobilenet_v1_1.0_224_quant.tflite INFO: resolved reporter INFO: Created TensorFlow Lite delegate for NNAPI. INFO: Use NNAPI acceleration. INFO: Applied NNAPI delegate. INFO: invoked INFO: average time: 4649.78 ms INFO: 0.768627: 653 military uniform INFO: 0.105882: 907 Windsor tie INFO: 0.0196078: 458 bow tie INFO: 0.0117647: 466 bulletproof vest INFO: 0.00784314: 835 suit real 0m4.757s user 0m4.655s sys 0m0.096s root@imx8mpevk:/usr/bin/tensorflow-lite-2.5.0/examples# time ./label_image -a 1 -w 0 -p 1 -c 4 INFO: Loaded model ./mobilenet_v1_1.0_224_quant.tflite INFO: resolved reporter INFO: Created TensorFlow Lite delegate for NNAPI. INFO: Use NNAPI acceleration. INFO: Applied NNAPI delegate. INFO: invoked INFO: average time: 1164.36 ms INFO: 0.768627: 653 military uniform INFO: 0.105882: 907 Windsor tie INFO: 0.0196078: 458 bow tie INFO: 0.0117647: 466 bulletproof vest INFO: 0.00784314: 835 suit real 0m4.768s user 0m4.663s sys 0m0.092s root@imx8mpevk:/usr/bin/tensorflow-lite-2.5.0/examples# time ./label_image -a 1 -w 0 -p 1 -c 10000 INFO: Loaded model ./mobilenet_v1_1.0_224_quant.tflite INFO: resolved reporter INFO: Created TensorFlow Lite delegate for NNAPI. INFO: Use NNAPI acceleration. INFO: Applied NNAPI delegate. INFO: invoked INFO: average time: 3.30189 ms INFO: 0.768627: 653 military uniform INFO: 0.105882: 907 Windsor tie INFO: 0.0196078: 458 bow tie INFO: 0.0117647: 466 bulletproof vest INFO: 0.00784314: 835 suit real 0m33.128s user 0m7.516s sys 0m1.590s |
openVX를 통해 처리하는 것 같은데 처음 처리하면 그래프 처리 결과를 스토리지에 저장한다고.
| 11.3 Hardware accelerators warmup time For both Arm NN and TensorFlow Lite, the initial execution of model inference takes longer time, because of the model graph initialization needed by the GPU/NPU hardware accelerator. The initialization phase is known as warmup. This time duration can be decreased for subsequent application that runs by storing on disk the information resulted from the initial OpenVX graph processing. The following environment variables should be used for this purpose: VIV_VX_ENABLE_CACHE_GRAPH_BINARY: flag to enable/disable OpenVX graph caching VIV_VX_CACHE_BINARY_GRAPH_DIR: set location of the cached information on disk For example, set these variables on the console in this way: export VIV_VX_ENABLE_CACHE_GRAPH_BINARY="1" export VIV_VX_CACHE_BINARY_GRAPH_DIR=`pwd` |
[링크 : https://www.nxp.com/docs/en/user-guide/IMX-MACHINE-LEARNING-UG.pdf]
'embeded > i.mx 8m plus' 카테고리의 다른 글
| i.mx8m plus win iot 실행 (0) | 2023.02.23 |
|---|---|
| i.mx8 tensilica dsp (0) | 2023.02.07 |
| i.mx8m plus win iot (0) | 2023.02.02 |
| imx 8m plus NPU 에러 추적 (5) | 2021.10.14 |
| i.MX 8M PLUS (0) | 2021.10.13 |