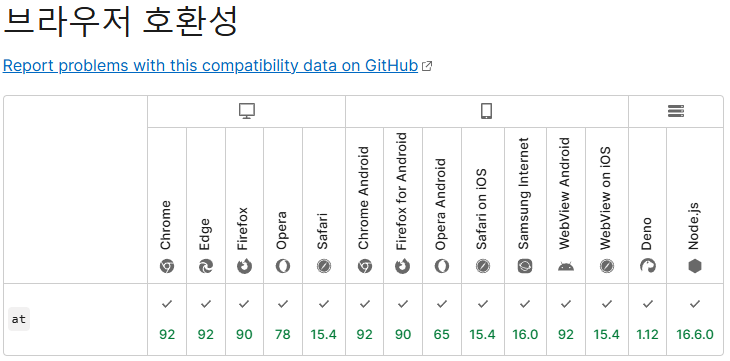
구버전의 javascript 라던가 python에 필요한 기능이 있을 경우 새로운 기능을 확장해주는 것을 polyfill 이라고 하는 듯.
| In software development, a polyfill is code that implements a new standard feature of a deployment environment within an old version of that environment that does not natively support the feature. Most often, it refers to JavaScript code that implements an HTML5 or CSS web standard, either an established standard (supported by some browsers) on older browsers, or a proposed standard (not supported by any browsers) on existing browsers. Polyfills are also used in PHP and Python. |
[링크 : https://en.wikipedia.org/wiki/Polyfill_(programming)]
'Programming > web 관련' 카테고리의 다른 글
| css 캐로젤 (0) | 2024.11.12 |
|---|---|
| webgl + three.js를 이용한 GL 공부하기 (feat 클로드) (0) | 2024.10.18 |
| 웹 브라우저에서 웹 캠 띄우기 (0) | 2024.09.24 |
| three.js (0) | 2024.09.19 |
| XMLHttpRequest 가로채기 (0) | 2024.07.19 |